A few days ago, about a dozen articles and campaign sites criticising EU plans for copyright censorship machines silently vanished from the world’s most popular search engine. Proving their point in the most blatant possible way, the sites were removed by exactly what they were warning of: Copyright censorship machines.
Among the websites that were made impossible to find: A blog post of mine in which I inform Europeans about where their governments stand on online censorship in the name of copyright and a campaign site warning of copyright law that favors corporations over free speech.
 Was this a brazen attack on open, democratic debate by someone in the media industry, abusing copyright enforcement tools in an attempt to silence those opposing their lobbying interests – or was it an unbelievably coincidental technical mistake?
Was this a brazen attack on open, democratic debate by someone in the media industry, abusing copyright enforcement tools in an attempt to silence those opposing their lobbying interests – or was it an unbelievably coincidental technical mistake?
One thing’s for certain: This incident gives us a chilling taste of what we’re in for if the European Parliament passes the upload filter law currently under consideration. It’s a call to arms to continue fighting against automated copyright filters. We know now better than ever: They invariably lead to censorship. Join the Europe-wide protests on August 26!
Today’s “copyright censorship light” is bad enough
 Rogue copyright bot
Rogue copyright botIllustration credit: Topple Track + icon by Freepik from flaticon.com
Under current US law, Google allows a number of companies to directly and without oversight remove sites from its search index, based purely on the claim that copyrights are being infringed. In effect, a handful of media companies have control over what we can – and can’t – find online.
One of them is Symphonic Distribution, who offer a service called “Topple Track” . This service sent a notice to Google on July 22 falsely claiming that my blog post and a number of other sites were somehow infringing on the copyright of an Australian TV starlet. Automated systems at Google honored the claim and delisted the pages, sight unseen.
If humans had been involved at any point in this process, the absurdity – or maliciousness – of this request would have immediately been spotted. But they weren’t. There are no checks and balances in place. Copyright enforcement has been automated, and no system either at services like Topple Track or at platforms like Google is able to prevent even such blatant mistakes – or such blatant abuse.
Topple Track boasts that they’ve removed over 7 million links from search engines for their music industry clients, and that 99% of their removal requests were honored. With their service now exposed to be so obviously dysfunctional, it’s unknowable how many more of these takedowns were fraudulent, and how many more articles are wrongly “shadowbanned” from the internet without their authors even being aware.
After the EFF uncovered further fraudulent removals by Topple Track and TorrentFreak covered the story, Google reportedly terminated its trusted partnership with the company. But still, as of this writing, my blog post remains unlisted on Google Search. Incredibly, not even when a company is exposed for issuing abusive takedowns are the websites they’ve previously ordered removed reinstated. Each individual author must actively put up a fight to restore the findability of their free speech. (Update: The page seems to be back in the Google index now.)
EU plans would make this much worse
On September 12, the EU Parliament will vote (one more time) on whether to force internet platforms to install upload filters.
With upload filters, platforms won’t even wait for complaints by media companies to remove your posts. Instead, your expression won’t even go online in the first place unless it passes a check against databases submitted by media companies. And you can be sure that these databases will be just as filled with junk and fraud.
Upload filters would give media companies even more direct control over the internet. All of us who post and upload content will be considered guilty until proven innocent, while media companies will continue to face no consequences for abusing the system. There’s no doubt what they would lead to: Even more censorship.
EU lawmakers must learn from this incident – and from the countless other documented failures of automated filtering: Automated copyright enforcement doesn’t work. Upload filters severely threaten our freedom of speech. They must be rejected.
You can help make that happen:
 Please join the protests happening all across Europe on Sunday, August 26 to stop upload filters from becoming EU law. Check SaveYourInternet.today for information on an event near you!
Please join the protests happening all across Europe on Sunday, August 26 to stop upload filters from becoming EU law. Check SaveYourInternet.today for information on an event near you!
To the extent possible under law, the creator has waived all copyright and related or neighboring rights to this work.
Hello,
thanks for pointing it out. IMVHO we need many different things in time and space.
From politics we need a clear reaffirmation that public services must be public, so roads must be public, water supply must be public, COMMUNICATIONS must be public. Having a government-owned telcos does not imply that private ISP cease to exists but simply that a universal, State-owned, basic service (for instance 10MBps symmetric for homes, 4G with around the same available bandwidth) will be available to anyone in a country and paid by taxes.
On service side states must enforce Free Software and Open Hardware simply because we can’t accept that our *states systems*, *military systems*, banking systems etc run on closed box no one but the OEM know really how they work (recent Intel CPUs bugs just an example).
A third, longer and even more complex point is education: schools need teachers and courses about IT with FreeSoftware and teachers are the hardest point: we do not have them. At least we have too few teachers.
On technical side we need to promote working decentralized solution like ancient, fully working and effective mails and newsgroups, used on our PCs not only via someone’s webmail services. So we still depend on someone but no-one hold OUR data without our control. On the development side we must keep going to look fully distributed solutions. Ancient Plan9 was probably the best operating systems (used still today in academia and for few HPC tasks like IBM supercomputers), we need to rediscover that also.
Many do not know IT history but in the past we develop free software, in the USA, non un the URSS, and in this era we see an incredible growth of technology so this model is not utopic but is a working, effective, model for both society and business.
Sorry for my English
Verstehe ich nicht. Worin besteht die Zensur jetzt in diesem Fall?
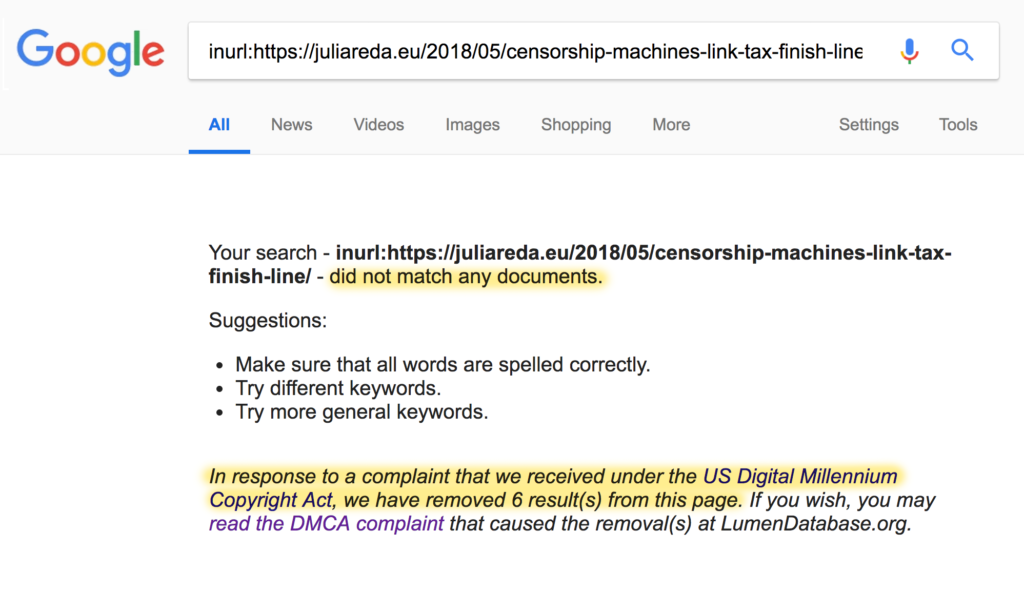
Da steht in dem Screenshot
Your search – inurl:https://juliareda.eu/2018/05/censorship-machines-link-tax-finish-line/ – did not match any documents
url:https://juliareda.eu/2018/05/censorship-machines-link-tax-finish-line/ funktioniert einwandfrei
Ist inurl: ein gültiges Prefix bei der Google-Suche? Ich kann mit inurl: nix finden.
Seit dem Tag, an dem dieser Post veröffentlicht wurde, scheint die Seite wieder im Google-Suchindex zu sein. Inurl ist ein gültiges Prefix.
Hallo Julia,
ich kann das nicht verifizieren. Sowohl mit Google als auch mit der alternativen Suchmaschine ixquick.de wird der Ausdruck gefunden.
Mit freundlichen Grüßen
Helmut Ott
Seit dem Tag, an dem dieser Post veröffentlicht wurde, scheint die Seite wieder im Google-Suchindex zu sein.
Not sure why you didn’t link to the DMCA complaint that caused the takedown of this and related links. It’s this one: https://lumendatabase.org/notices/16954705
Hello,
First, admirations on the position – I completely agree that discussion is the way for resloving such matters. However, this story for me is a clarion call for more regulation. Right now Google removed your content from search results by applying the DMCA without any notification to you. This does not seem normal to me – in terms of simple ethics, and of formal legal approach.
Censorship machines exist right now – and the problem is putting a leash on them, instead of leaving the matter to platforms. Because platforms create the censorship machines in the first place – because they have bigger clients than you and me, and given the opportunity, they will serve their interest.
Regulation is the tool that might give us some tools against this – because if the US market shows one thing, it is that self-regulation is a dream that will not become reality.
Hello Julia Reda,
I’ve watched on yesterday’s Tagesthemen that the EU copyright Proposal has gone through the EU Parliament! Where do we stand or leave us now as a plain user!? Is there anything we can still do about it, or is it Game over!?
There is going to be one final vote on the results of the negotiation between Parliament & Council (member state governments). Unfortunately both these institutions are now in favor of platform liability (which implies filtering) and the “link tax”. But we still have a chance to kill the entire bill – the vote will be just a few months before the next EU elections. Help make it a campaign topic!